Amazon ECS でのコンテナデプロイの高速化
この記事は同僚の Nathan Peck (@nathanpeck)が書いた記事 “Speeding up Amazon ECS container deployments” を翻訳し、加筆・修正したものです. 元記事を ECS ユーザに紹介する機会が何回かあったので、せっかくなので翻訳することにしました.
コンテナのオーケストレーションは非常に複雑な問題の一つです. アプリケーションコンテナのデプロイのために、相互にやり取りを行う複数の異なるコンポーネントが存在します. あなたのアプリケーションを実行したオーケストレータは、その実行されたアプリケーションが Web トラフィックを受け取る用意ができているかどうかについて判断する必要があります. その後そのアプリケーションはスケールダウンされたり、あるいは新しいバージョンのアプリケーションをロールアウトするために古いバージョンのアプリケーションを停止したりする必要があるでしょう. ここでも、オーケストレータはそのアプリケーションを停止して大丈夫かどうか判断する必要があります. ローリングデプロイによる新旧アプリケーションの入れ替えを実施している最中であっても、オーケストレータはあなたのアプリケーションが機能し続けることを目指すからです.
このような仕組みが機能する結果、コンテナのデプロイに想定よりも長い時間がかかっていると感じるような状況に出くわすことがあります.「新バージョンのコンテナのロールアウトに15分かかっているのはなんでだろう?」と考えたことはありませんか?もしそうなら、これは多くの場合あなたがコンテナオーケストレータの設定の一部を過度に「安全に」動くよう設定していることが原因です. 本記事では、Amazon ECS によるコンテナのデプロイ設定を、そのような「安全さ」を多少抑えた設定にすることでデプロイ速度を大幅に速くするためのテクニックを紹介していきます.
ロードバランサのヘルスチェック
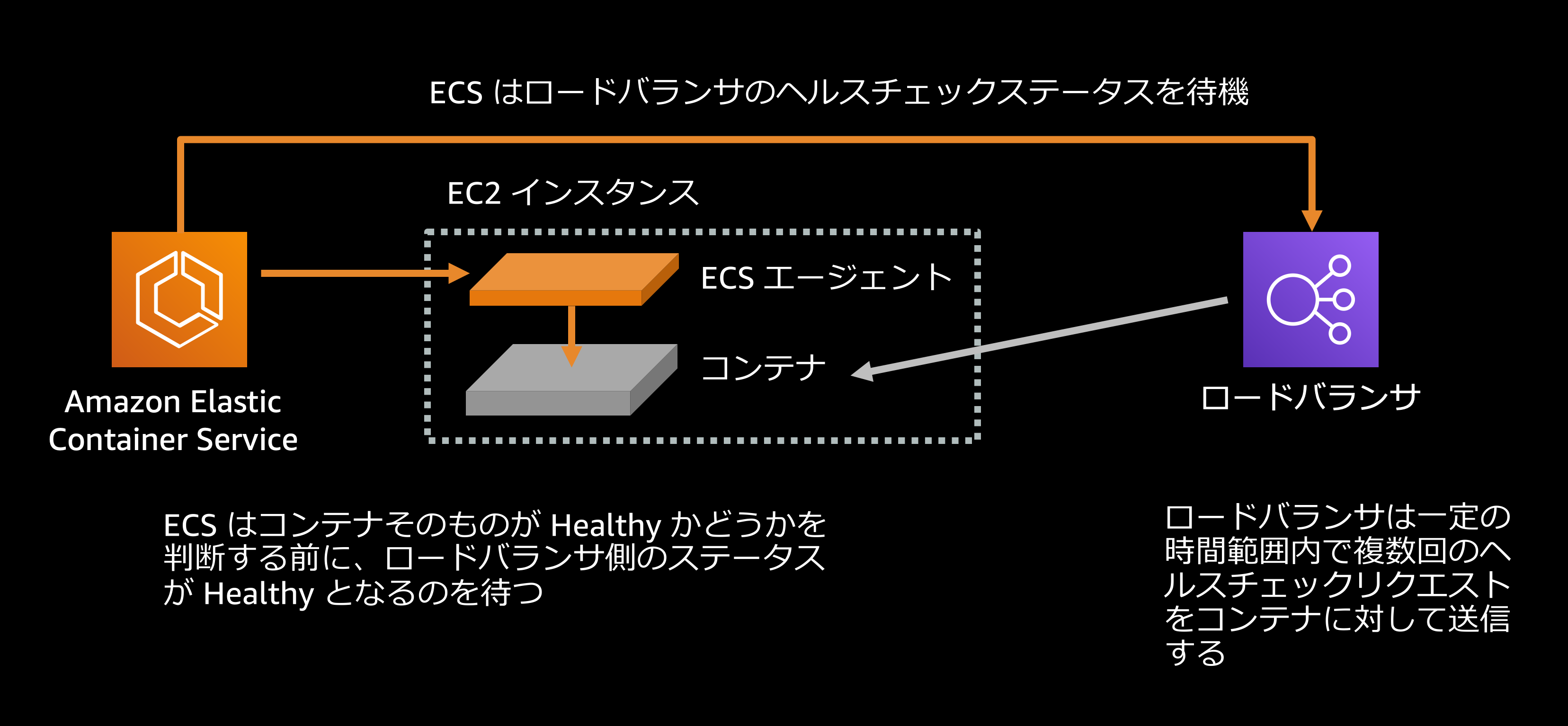
ロードバランサのヘルスチェックについて、安全性とデプロイ速度の観点からその設定をあらためて確認しておきたい項目は大きく2つあります:
ヘルスチェックのデフォルト設定値
HealthCheckIntervalSeconds: 30 秒 - ヘルスチェックの実施間隔秒数HealthyThresholdCount: 5 回 - ターゲットが Healthy とみなされるまでに必要なヘルスチェックの連続成功回数
参考 (ALB): ターゲットグループ > ヘルスチェックの設定 - Application Load Balancer 参考 (NLB): ターゲットグループ > ヘルスチェックの設定 - Application Load Balancer
デフォルトでは、ロードバランサがターゲットを Healthy と認識するまでに、30秒ごとのヘルスチェックが5回連続で成功する必要がある設定となっています. ここから予想される時間を簡単に計算すると、(5 * 30 / 60 = 2.5)、つまりターゲットがはじめて Healthy となるまでには少なくとも2分30秒かかることが分かります. Amazon ECS がコンテナが Healthy かどうかを判断する際にはこのロードバランサのヘルスチェックが通っていることもその基準の一つとして利用されますので、つまり ECS でデプロイされたロードバランサを利用するコンテナが Healthy となるまでには、少なくともデフォルトで2分30秒以上の時間がかかると言えます.
ほとんどのモダンなアプリケーションランタイムがそうであるように、もしあなたのアプリケーションがより早く起動とトラフィックを受け取ることができるものなのであれば、このヘルスチェックの設定を変更することによってコンテナが Healthy と認識されるまでの時間を短くすることができます.
ヘルスチェックをどんな設定値にするか
HealthCheckIntervalSeconds: 5 秒HealthyThresholdCount: 2 回
例えばさきほどの設定値をこのような値に変更すると、アプリケーションがロードバランサに登録されてから実際にトラフィックを受け取り始めるまでにかかる時間、そして ECS がコンテナが Healthy であると見なすまので時間を10秒程度にまで短縮できるわけです.
コラム - ALB と NLB の初期ヘルスチェックの仕様の違い
上記の説明では簡単のために単純にインターバル秒数と回数を掛け算して目安となる時間を算出しましたが、実は ALB と NLB ではターゲット登録後の初回ヘルスチェックの仕様と挙動に明確な違いがあります.
公式ドキュメントの ALB ターゲットヘルスステータスと NLB ターゲットヘルスステータスを比較確認すると分かりやすいのですが、ALB 側のドキュメントには『ターゲットがロードバランサーからリクエストを受信する前に、最初のヘルスチェックに合格する必要があります。ターゲットが最初のヘルスチェックに合格すると、ステータスは Healthy になります。』という記述が存在します.
これをもうちょっと別の表現で説明すると以下のような点が異なるということが分かります.
ALB - ターゲット登録後はじめて実行されるヘルスチェックがパスするとそのターゲットはすぐに Initial から Healthy ステータスに遷移し、ターゲットに ALB 経由のトラフィックが届くようになる
NLB - ターゲット登録後に実行されるヘルスチェックが HealthyThresholdCount 回パスするとターゲットが Initial から Healthy ステータスに遷移し、ターゲットに NLB 経由のトラフィックが届くようになる
ALB/NLB のヘルスチェックとターゲットのステータスには上記のような違いと関係性があるため、ALB を利用している場合にはみなさんの想定よりも早いタイミングでターゲットが Healthy になる可能性があります.
ロードバランサのコネクションドレイン
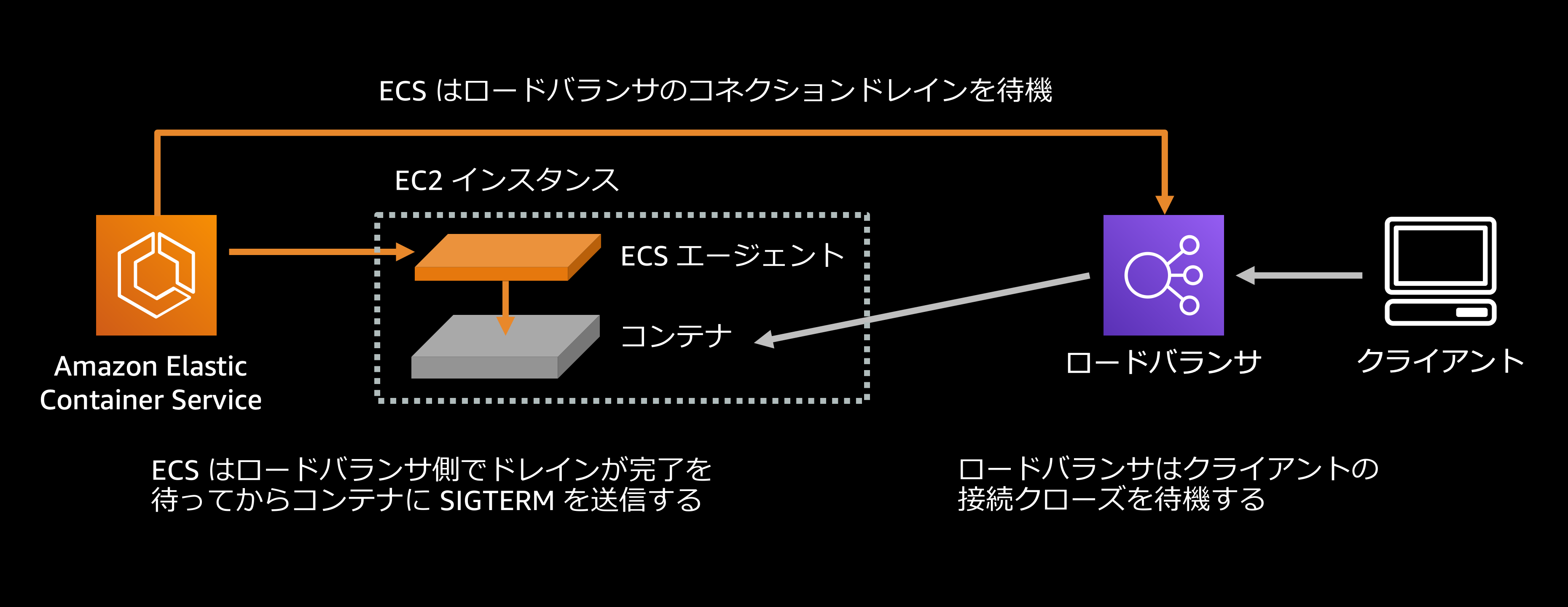
一般に、ブラウザやモバイルデバイスといったクライアントは、コンテナ内で実行されているサービスと持続的な接続を維持します. これは重要な最適化で、リクエストを送るたびにコネクションを再確立するのではなく、既に確立された接続を後続のリクエストに再利用できるということを意味します.
例えばコンテナを停止したいと思ったとき、ロードバランサに対してそのコンテナへのトラフィックのルーティングを止めるように指示すると、ロードバランサはそのコンテナに対する新しいコネクションの確立をやめる一方で、既存のコネクションについてはそれらが自発的に閉じられることを待機します. これら既存のコネクションは一定時間の経過後に強制的に切断されますが、このように強制的な接続の破棄まで一定の待機時間を設けることを、AWS のロードバランシングサービスでは『登録解除の遅延 (Deregistration Delay)』と呼びます.
コネクションドレインのデフォルト設定値
deregistration_delay.timeout_seconds: 300 秒 - ロードバランサからの登録解除前にロードバランサが待機する秒数
参考: ターゲットグループ > ターゲットグループの属性 - Application Load Balancer
デフォルトでは、ロードバランサは既存のコネクションが自発的に閉じられるまで最大300秒(つまり5分)待ち、その後強制的な切断を行う設定になっています. ECS はロードバランサからの登録解除完了を待ってからコンテナに対して SIGTERM を送信するため、この待ち時間の最中のリクエストについてはドロップされることはありません.
もしあなたのサービスが平均的にレスポンスタイムが短い REST API のようなものなら、害なくこの遅延時間を減らすあるいは完全に削ってしまえるかもしれません. 注意 - ファイルアップロードやストリーミングのようなリクエスト・レスポンスの正常な処理に長時間のコネクション維持を必要としうるサービスでは、適切なアプリケーション改修なしにロードバランサの登録解除の遅延時間を短くすることは問題が発生する可能性があることに気をつけましょう.
コネクションドレインをどんな設定値にするか
deregistration_delay.timeout_seconds: 5 秒
この設定変更によってロードバランサが既存のコネクションを強制的に切断するまでの待ち時間(コネクションドレイン)が5秒になり、ECS がすぐにタスクを停止できるようになります.
SIGTERM シグナルへのアプリケーションの反応性
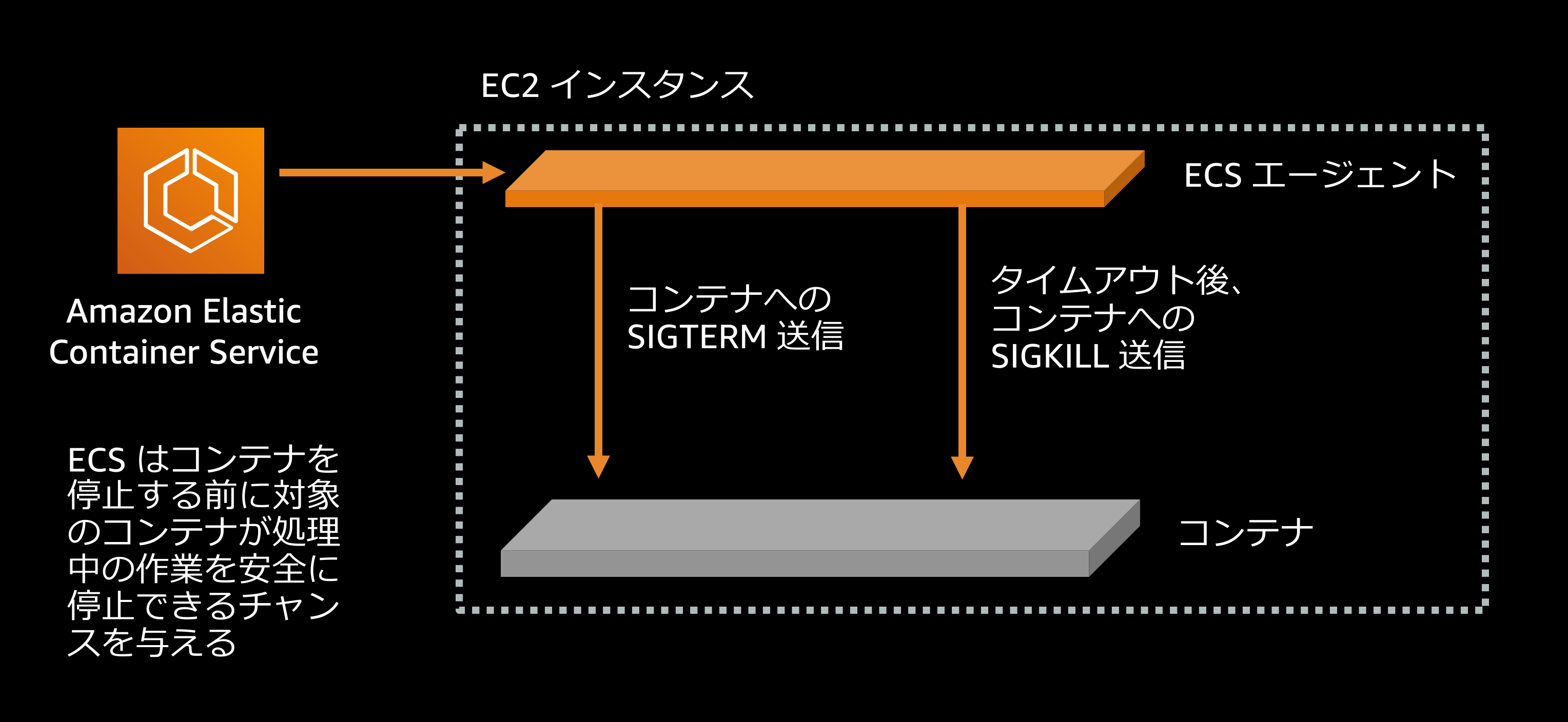
ロードバランサによるコネクションドレインが完了すると、ECS はタスクを止めるために(最初に行うことの一つとして) SIGTERM シグナルをそのタスクへ送信します. これはコンテナ化されたアプリケーションが現在行っている処理を完了させて終了する必要があることを知らせる “friendly reminder” と言えます. しかし、このシグナルを無視してしまうアプリケーションやアプリケーションフレームワークも数多く存在します. ECS は SIGTERM シグナルを送信したあと、アプリケーションが行儀良く終了処理を済ませてから終了するのを一定時間待ちますが、その待ち時間を過ぎるとアプリケーションプロセスを強制的に停止するために SIGKILL シグナルを送信します. デフォルトではこの待ち時間は30秒に設定されています.
SIGKILL までの待ち時間のデフォルト設定値
ECS_CONTAINER_STOP_TIMEOUT: 30 秒 - 正常に自己終了しないコンテナを強制終了するまでの待機時間
参考: Amazon ECS コンテナエージェントの設定 - Amazon ECS 開発者ガイド
この設定値は Amazon ECS コンテナエージェントの実行時環境変数、あるいは /etc/ecs/ecs.config ファイルへの設定値の追記によって変更できますが、この値をデフォルト値よりも低く設定することでコンテナが安全に終了するまでの待ち時間を短くできます.
SIGKILL までの待ち時間をいくつに設定するか
ECS_CONTAINER_STOP_TIMEOUT: 2 秒
例えばこの設定値をとると、ECS はコンテナに対して SIGTERM を送信したのちにその停止を2秒間待ち、待ち時間の経過後にコンテナが終了できていない場合は SIGKILL シグナルを送信してコンテナを強制的に停止します. 理想的には、この待ち時間はもっとも遅いレスポンスとなる処理にかかる時間の少なくとも2倍程度の長さに設定されていることが望ましいと言えます. つまり、ここで例に挙げた設定値(2秒)は、アプリケーションが1秒以内にレスポンスを返すと仮定した場合にはすべての処理中のリクエストに対してレスポンスを返しきってからプロセスを終了するのに十分な時間と言えるでしょう.
また、本来的にはアプリケーション自身がシグナルに対して適切に反応できることこそが重要です. もしアプリケーションコードそのものを変更できるのであれば、SIGTERM シグナルに反応して安全にアプリケーションを停止する実装を加えましょう. 例えば Node.js では次のような実装が挙げられます:
process.on('SIGTERM', function() {
server.close();
})
Node.js のこの例では、HTTP サーバは新しいリクエストの受け取りを止め、処理中のリクエストへのレスポンスを完了させることで、イベントループに処理すべきものがなくなった Node.js アプリケーションが安全に停止されます. このような実装をアプリケーションに加えることで、SIGKILL シグナルが送られてくることなく安全にアプリケーションが自己終了できるようにすることが望ましいでしょう.
コラム - AWS Fargate で SIGKILL までの待ち時間を設定したい場合は?
ECS タスクを AWS Fargate で実行している場合、ユーザは Amazon ECS コンテナエージェント(実際には Fargate 環境で動いている Fargate コンテナエージェント)の設定値を直接変更できません. Fargate 環境で ECS_CONTAINER_STOP_TIMEOUT に該当する設定値を変更するには、タスク定義のコンテナタイムアウト設定を指定します. 詳細は 「タスク定義 > タスク定義パラメータ > コンテナのタイムアウト - Amazon ECS 開発者ガイド」配下にある stopTimeout 設定をご覧ください.
追記コラム - SIGTERM タイムアウト設定値についての考え方
本記事公開後、読者の方から次のような質問をいただいたので追記します. (2021/4/20)
Q: ここまでの説明を元に考えると、コンテナに SIGTERM が飛んでくるのはロードバランサでドレインを行ったあとのはずなのに、SIGKILL までの時間を HTTP request/response にかかる時間を元に決める必要はありますか?
ALB などをアプリケーションコンテナの前段に置いている場合はご賢察の通り、HTTP request/respose を元に SIGKILL までの時間を決める必要はないですね. しかし、例えば VPC 内でのやり取りを前提として、ALB ではなく ECS Service Discovery (サービス検出)を使っているようなケースでは、そのアプリケーションの HTTP request/response 処理の中で最も要する時間が長いものをベースに SIGTERM シグナルのタイムアウトを決めることが引き続き有効に機能します.
せっかく追記するので、他の例として HTTP request/respose を前提とした Web アプリケーションの類ではない、例えば SQS キューのメッセージを処理をするようなバッチアプリケーションを挙げておきましょう. このようなタイプのアプリケーションにおいては、仮に一つの SQS キューメッセージを処理するのに最大で30秒かかるとすると、SIGTERM のタイムアウトにはその倍の60秒を検討するというような形での適用方法が考えられますね.
コンテナイメージ pull の挙動設定
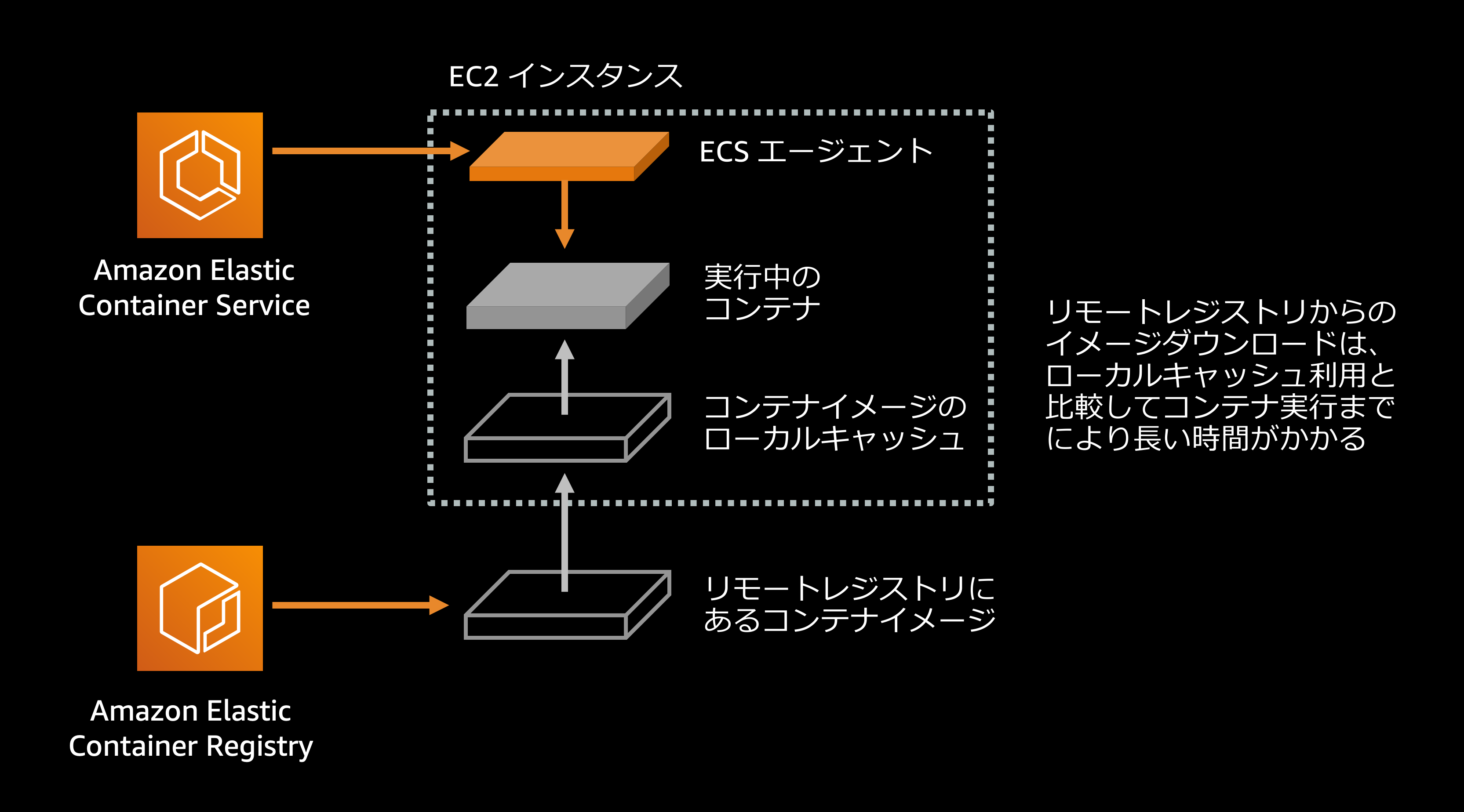
ここで紹介するテクニックは ECS/EC2 環境でコンテナを実行している場合に利用できるものです.
デフォルトでは、ECS コンテナエージェントはタスクを実行する際に常にコンテナイメージレジストリからコンテナイメージを pull (ダウンロード)するよう動作します. しかし、仮にあなたが良くデザインされたコンテナイメージのタグ付け戦略(例えば新しいコンテナイメージには毎回新しいタグを付けるような)を用いてコンテナを利用している場合、この ECS コンテナエージェントのデフォルトの挙動は不要なわけです. 逆に、latest イメージタグを毎回上書きして使っているような状況ではこのデフォルトの挙動が意味を持ちます. latest タグを利用することはアンチパターンですので、毎回ユニークなイメージタグを利用する方式に変更すると同時に ECS コンテナエージェントのイメージ pull の挙動を変更しましょう.
イメージ pull 挙動のデフォルト設定
ECS_IMAGE_PULL_BEHAVIOR:default- イメージ pull の挙動設定 (defaut / always / once / prefer-cached)
参考: Amazon ECS コンテナエージェントの設定 - Amazon ECS 開発者ガイド
コラム - deafult と always の違いは?
どちらもコンテナの起動前に必ずイメージの pull を試みる点については同じですが、default がイメージの pull に失敗した場合にキャッシュの利用を試みるのに対し、always はイメージ pull に失敗してもイメージキャッシュは参照せず、ECS タスクの起動に失敗したというステータスになります.
推奨されるイメージ pull 挙動の設定
ECS_IMAGE_PULL_BEHAVIOR:prefer-cachedあるいはonce
この設定によって ECS はリモートレジストリからダウンロードするのではなく EC2 ホストのディスクキャッシュに存在するダウンロード済みのコンテナイメージを利用します. これによりタスクの起動速度改善が見込め、とくに pull に10-20秒かかるような大きなサイズのコンテナイメージをネットワーク越しに pull するようなケースにおいて特に有効です.
前述した通りイメージタグを毎回新しいものを利用する適切な戦略を採っている場合には、新しいバージョンをデプロイするたびに異なるイメージタグが利用されるためこのイメージキャッシュはあまり役に立たないように感じる方もいるかもしれません. しかし、実際にはコンテナワークロードの運用において同じコンテナイメージを設定だけを変更してロールアウトするようなシチュエーションは数多く発生するため、イメージキャッシュはやはり有効と言えます.
コラム - AWS Fargate ではイメージキャッシュは効きませんよね?
AWS Fargate ではタスクと足回りのマシンは 1:1 で割り当てられ、またタスクを起動するたびにフレッシュなホストマシンストレージを用意するため現時点ではイメージキャッシュを利用できません. AWS コンテナサービスチームの GitHub 公開ロードマップに作成されているこのリクエストアイテム “[Fargate/ECS] [Image caching]: provide image caching for Fargate. #696” もぜひウォッチしてください😊
デプロイの「ステップ」
デプロイ速度の改善を目指す際には、あるサービス更新のロールアウトが完了するまでにコンテナオーケストレータが経る必要があるステップがどれくらいの数あるか、というのもぜひ考慮しておきたい重要な最適化ポイントの一つです. 新バージョンのロールアウト中であってもそのアプリケーションの uptime が100%であることを維持することも、優れたコンテナオーケストレータのゴールの一つだからです. ここではまずはオーケストレータが次の2つのステップを実行したとイメージしてみましょう:
- 旧バージョンのコンテナを停止する
- 新しいバージョンのコンテナを実行する
このケースでは、ステップ1と2の間にアプリケーションが一切実行されていない時間帯が存在し、ということはそのアプリケーションのユーザの手元ではエラーは発生するでしょう.
理想的にはオーケストレータは次のようなステップで動作すべきです:
- 新バージョンコンテナを旧バージョンコンテナと並行して実行する
- 新バージョンコンテナが Healthy であることを待ち、確認する
- 旧バージョンコンテナを停止する
どのようなデプロイ設定をしているか、あるいはその時点の ECS クラスタにデプロイ可能な領域(vCPU、メモリなど)が空いているかなどにも依存しますが、すべての古いタスクを新しいタスクで置き換えるにはこのようなステップを複数回繰り返す必要があるでしょう. そのようなオーケストレータのステップ数に影響しうるデプロイ設定の例として、ここでは ECS サービスをローリングデプロイする際の挙動を設定できる minimumHealthyPercent と maximumPercent のデフォルト値を見てみましょう:
minimumHealthyPercent と maximumPercent
minimumHealthyPercent: 100% - デプロイ処理中に最低限実行状態が維持される必要があるタスクの下限数 (desiredCountに対する割合)maximumPercent: 200% - デプロイ処理中に ECS が desiredCount を超えてデプロイして良いタスクの上限数 (desiredCountに対する割合)
参考: サービス > デプロイ設定 - Amazon ECS 開発者ガイド
これらの設定値によって実際のどのような挙動になるかをイメージしてみましょう. ここでは仮にある ECS サービスが6つの「オレンジ」タスクを実行しており、そのクラスタには最大で8タスクまでデプロイできるキャパシティがあったとします. また、デプロイ設定の minimumHealthyPercent に 100%、つまりデプロイ中でも常に desiredCount = 6 と同数の実行中タスクを維持する必要がある設定にしていたとします.
Imagine a service that has 6 orange tasks, deployed in a cluster that only has room for 8 tasks total. Additionally the deployment settings don’t allow the deployment to go below 100% of the 6 desired tasks:
最大8タスク配置可能なクラスタで minimumHealthyPercent = 100% に設定した場合
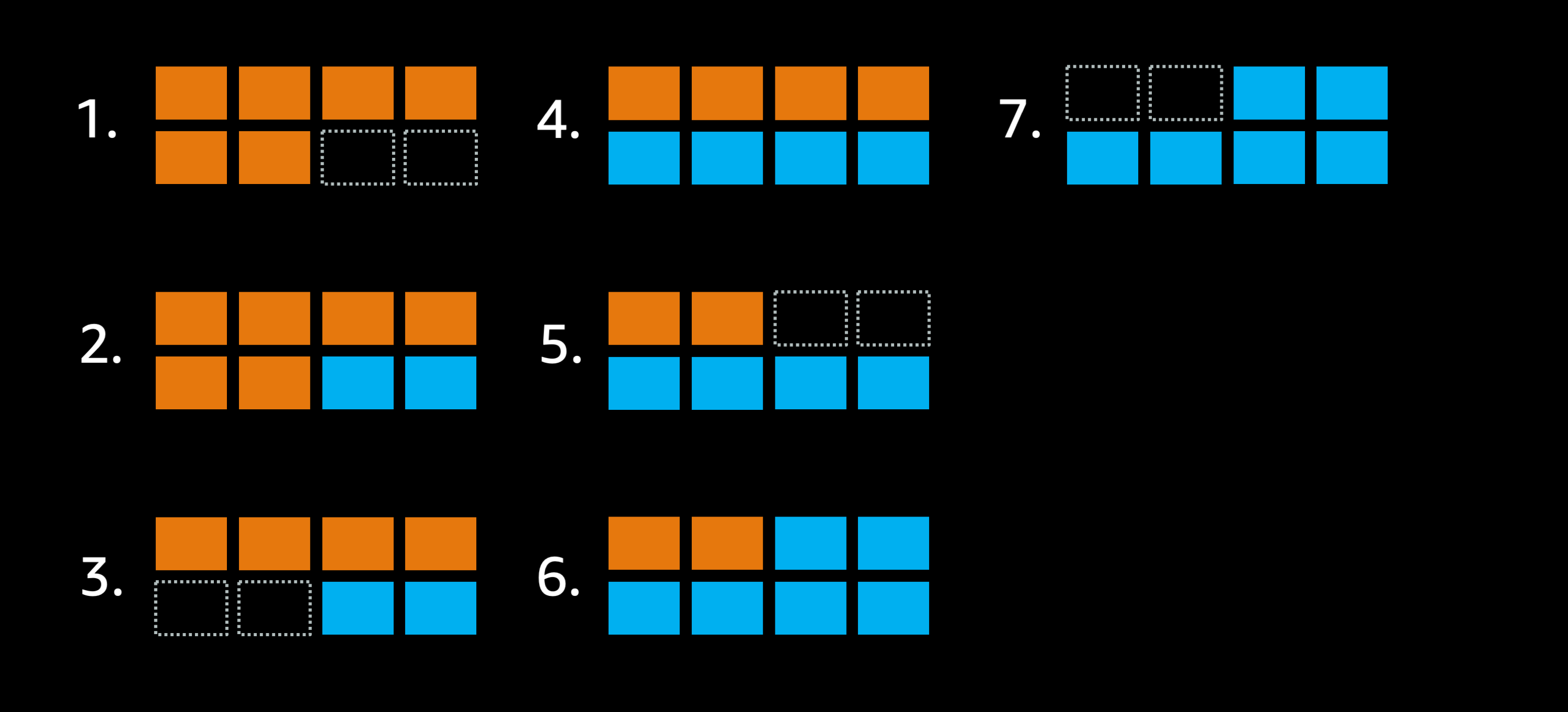
- ゴールはこれらのオレンジデプロイメントを青で入れ替えることです.
minimumHealthyPercentの設定値が 100% になっているので、実行中のタスク数=6をスケジューラは維持しようとします. つまり、ここでは既存のオレンジタスクを停止することはできません. そこでクラスタの空きキャパシティを使ってまずは2つの青タスクを実行します.- 実行した青タスクが Healthy になると、この時点でスケジューラはオレンジタスクを2つまで止めることができるようになります. しかしここでも実行中タスク数を6に保つ必要があるため、停止できるオレンジタスクは2つまでです.
- ECS はあと4つのオレンジタスクを青タスクで置き換える必要がありますが、ここでも次にとれるアクションは空きキャパシティを使って2つの青タスクを実行することです.
- 追加で起動した2つの青タスクが Healthy になったので、2つのオレンジタスクを停止できます.
- これまで同様、空きキャパシティに2つの青タスクを実行します.
- 最後に起動した青タスクが Healthy になれば、最終的にスケジューラは残された2つのオレンジタスクを停止してデプロイ処理が完了します.
このローリングデプロイのケースは6つのステップを通してクラスタ状態を変更していくことで完了しましたが、新しいタスクを実行した際にはそれらの新タスクが Healthy になるのを待つ(冒頭で触れたデフォルト値でロードバランサを使っている場合、この待ち時間には2.5分かかるかもしれません)ことになります. あるいは、旧タスクを停止する際にはロードバランサのドレインを待つ(こちらもデフォルト設定値だと5分ほど待たされるかもしれません)ことになります. また、ロードバランサに関する設定だけでなく、このアプリケーションが適切に SIGTERM シグナルに反応していなければ、コンテナを停止するたびにデフォルト設定ではさらに追加で30秒その停止を待たされることになります. ここで例に挙げたようなシンプルなローリングデプロイであっても、適切な設定なしにはその処理の完了に30分以上の時間がかかりうることが容易に想像できますね.
それでは、この minimumHealthPercent を 50% に変更し、デプロイ処理中に維持する必要があるタスク数を半分まで減らすとどのようになるか見ていきましょう:
最大8タスク配置可能なクラスタで minimumHealthyPercent = 50% に設定した場合
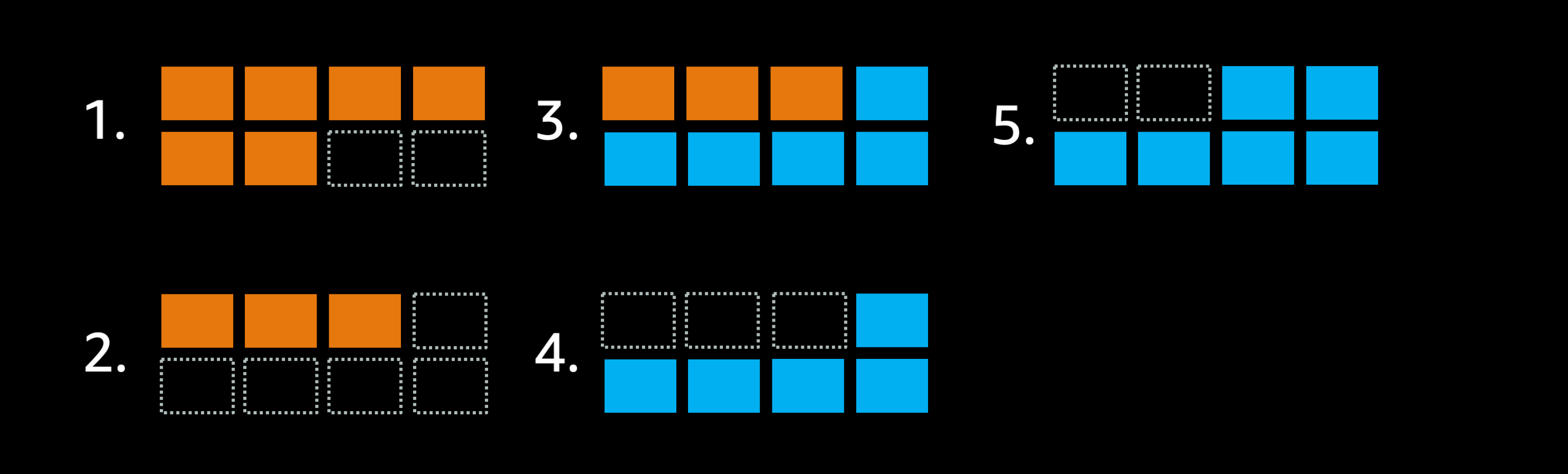
- ゴールは先ほどと同様、これらのオレンジデプロイメントを青で入れ替えることです.
- minimumHealthyPercent = 50% に設定されているため、スケジューラは6つあるオレンジタスクのうち3つのオレンジタスクを停止し、タスク3つ分の空きキャパシティがクラスタに追加で生まれます.
- これによりスケジューラは5つの青タスクを実行できます.
- ECS は残された3つのオレンジタスクを青タスクで置き換える必要がありますが、この3つのオレンジタスクを同時に停止します.
- 追加で起動が必要な青タスクは1タスクですので、それを起動してデプロイ完了です.
この設定では、前回6ステップ必要だったデプロイ処理が4ステップで完了しました.
仮にこのクラスタにもう少し余剰キャパシティを追加して全部で10タスクまで配置できるようにしたとすると、デプロイ処理は次のようになります:
クラスタの最大配置可能タスク数を8から10に拡張し、minimumHealthyPercent = 50% に設定した場合
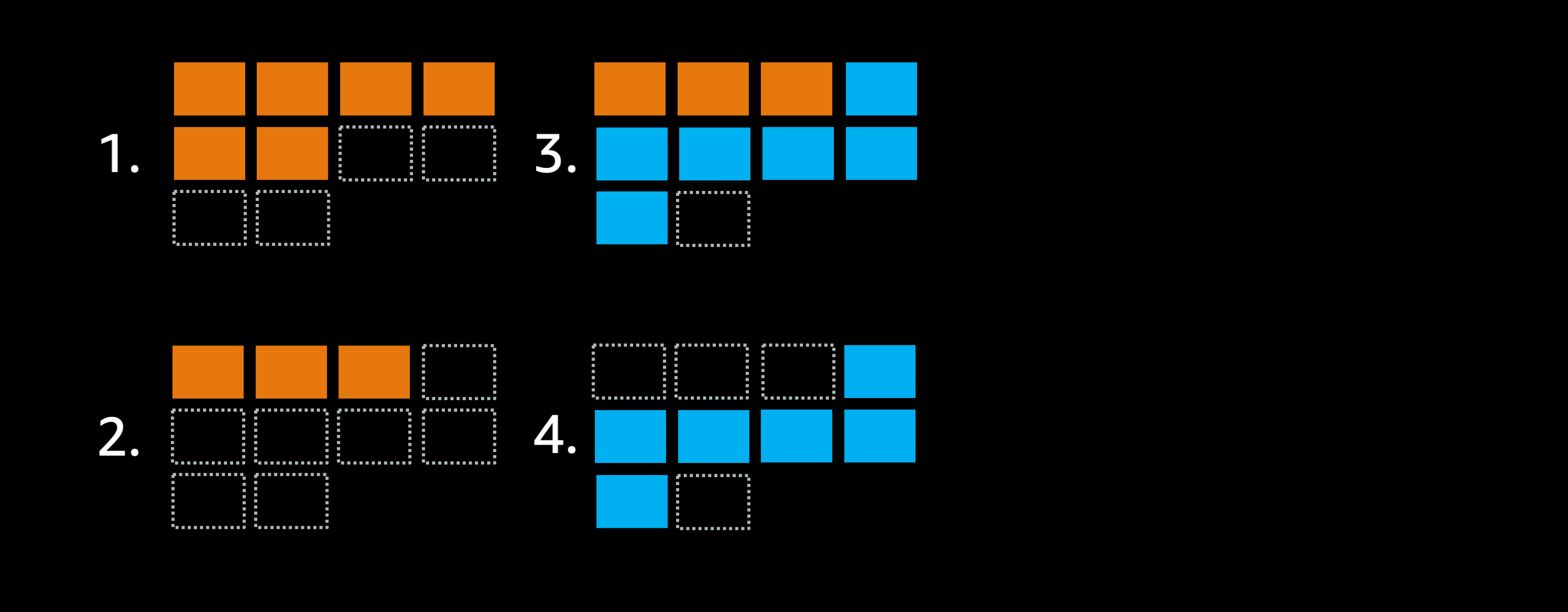
- ゴールはこれらのオレンジデプロイメントを青で入れ替えることです.
- minimumHealthyPercent の設定に従い、スケジューラは最大 50% までタスクを停止できるため、オレンジタスクを停止してクラスタの空きキャパシティを3タスク分増やします.
- これによりスケジューラは必要な青タスク6つを一度に起動できます.
- 最後の重要な仕事として、スケジューラは残されたオレンジタスクを停止します.
今回は3ステップでデプロイ処理が完了しました.
もしあなたのアプリケーションが比較的アイドル状態にあることが多いような場合、あるいは高い稼働状況にないような場合においては、例えば次に挙げる設定を利用して ECS が新しいタスクの配置前にまず古いタスクを停止することを許可し、それによりローリングデプロイによるデプロイ処理を一気に高速化できる可能性があります.
低稼働なアプリケーションのデプロイ高速化で検討したい設定値
minimumHealthyPercent: 50%maximumPercent: 200%
一方で、あなたのサービスが常に高い稼働状況にあるアプリケーションの場合には、たとえデプロイ処理中であっても必要なタスク数が維持されていなければその可用性やレイテンシに悪影響を及ぼす可能性があります. そのようなケースでは minimumHealthyPercent についてはデフォルト設定の 100% を利用しつつ、クラスタキャパシティに余裕を持たせ、ECS がより少ないステップ数でローリングデプロイの処理を完了できるよう構成する手段を検討してみると良いでしょう.
まとめ
いくつかのちょっとした設定変更でデプロイ速度が劇的に改善することはままあります. 本記事で紹介したテクニックがみなさんの Amazon ECS でのローリングデプロイ速度の高速化の手助けになると嬉しいです.
ダウンロード
記事内で利用したダイアグラムの元データはこちらからダウンロードできます.
📎 speeding-up-ecs-deployments-ja.pptx (4946 kb)